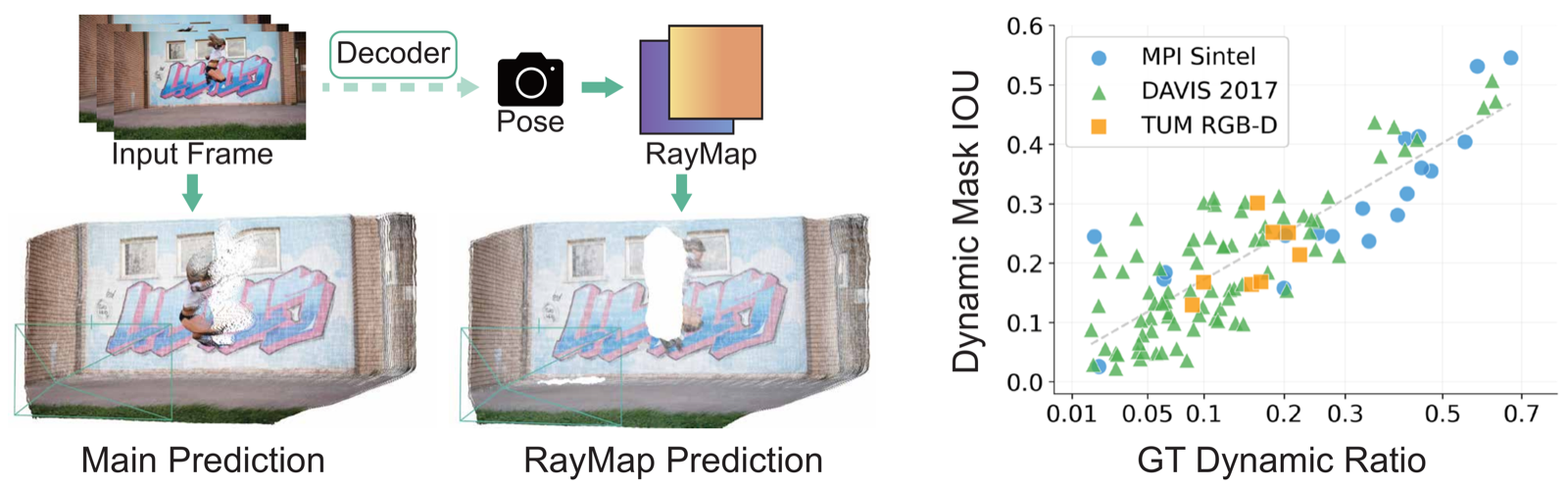
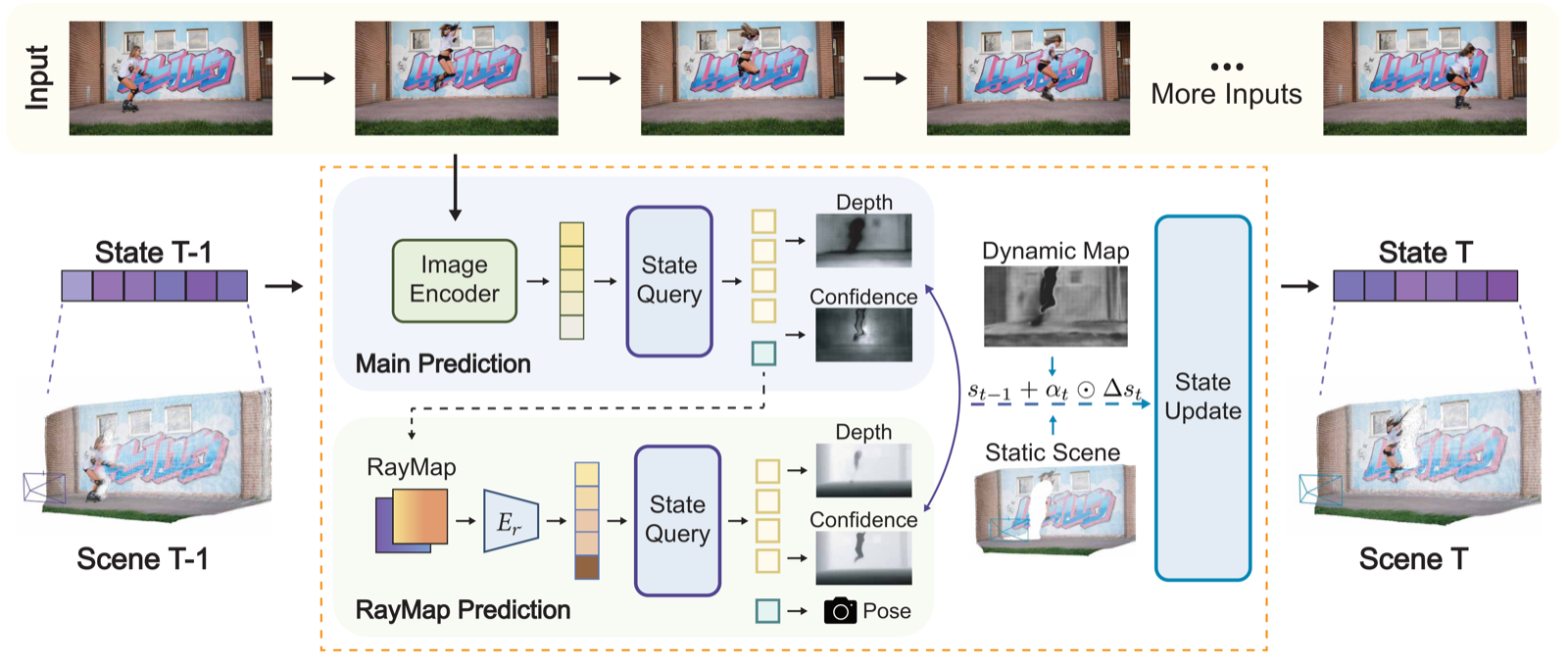
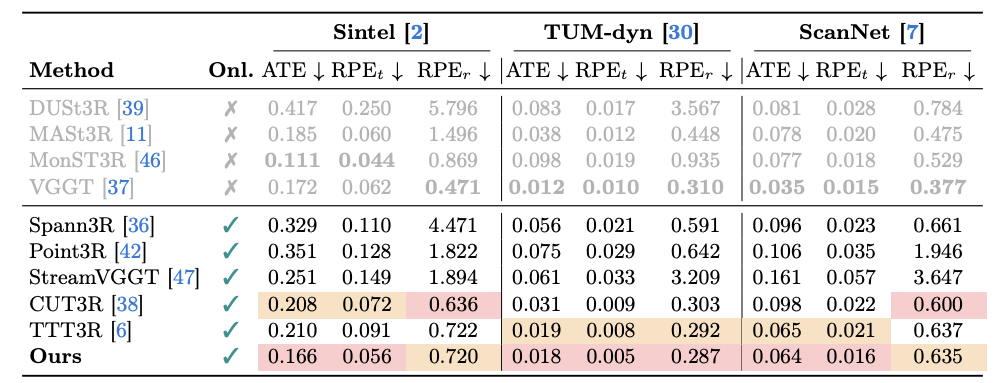
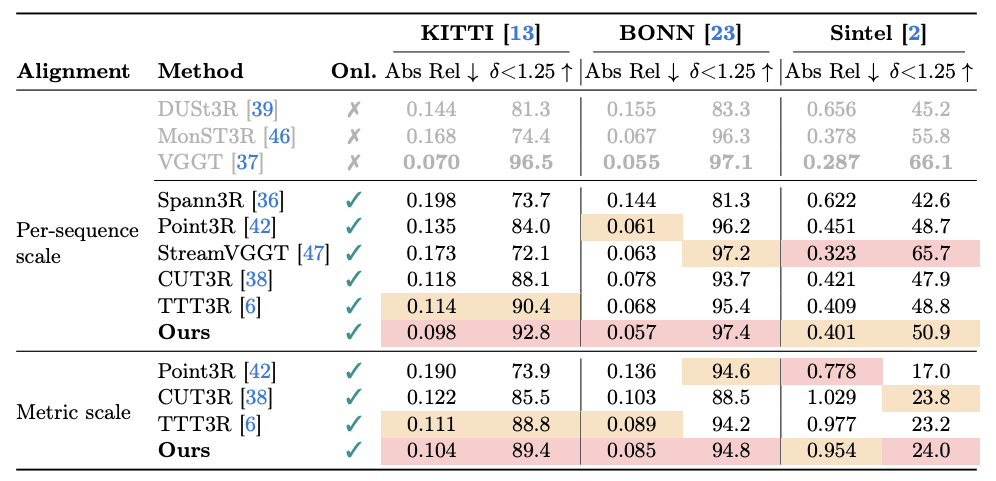
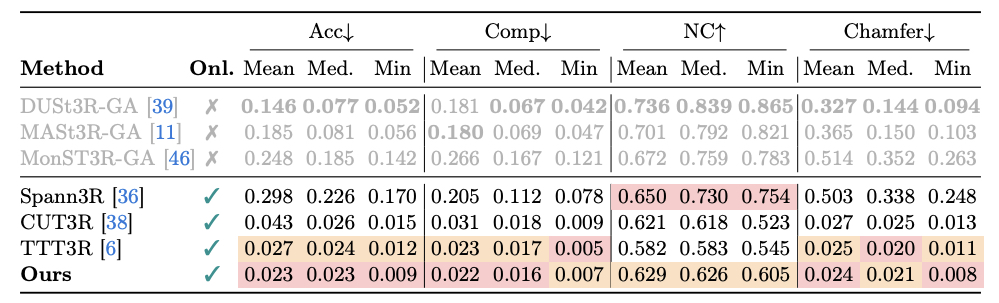
Streaming 3D Reconstruction for Dynamic Scenes. Existing streaming methods such as CUT3R and TTT3R can suffer from camera drift caused by moving objects. RayMap3R identifies and suppresses dynamic regions at inference time without additional training or external models, producing more stable trajectories and geometrically faithful reconstruction.